
はじめに
生成AIの進化により、業務の効率化が飛躍的に進んでいます。しかし、「AIを使って作成したコンテンツが、気づかないうちに他人の著作権を侵害してしまったらどうしよう…」と不安に感じる方も多いのではないでしょうか。
意図せず既存の著作物と似たものを作成・公開してしまうと、損害賠償請求などの法的なトラブルに発展するリスクがあります。この記事では、AIと著作権の関係性や侵害のリスク構造をわかりやすく解説し、安全に業務で活用するための具体的な対策やガイドラインのポイントをご紹介します。
生成AIにおける著作権侵害の構造
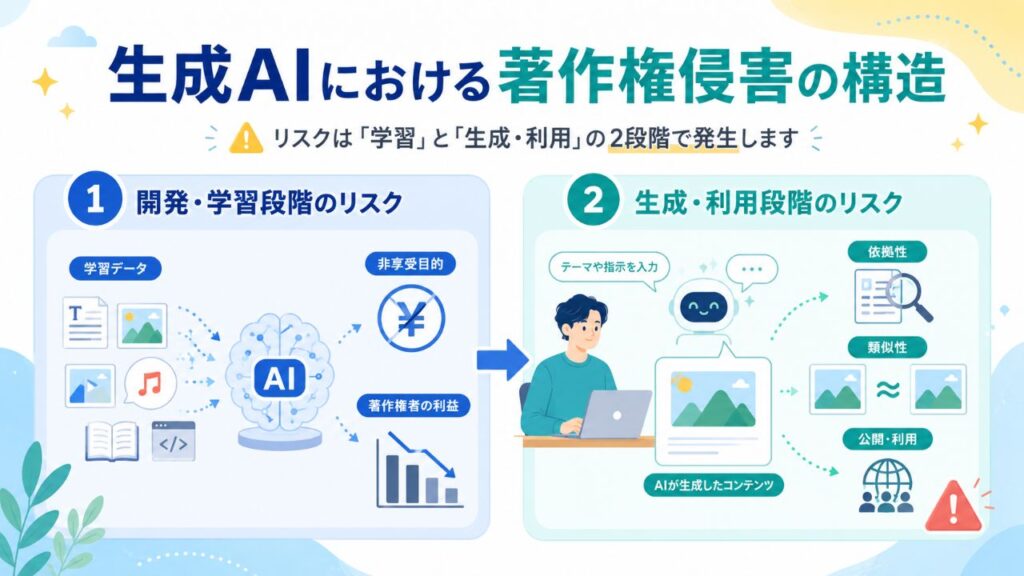
AIと著作権の関係を理解するためには、AIがコンテンツを作り出すまでのプロセスを2つの段階に分けて考えることが重要です。
1. 開発・学習段階のリスク
AIは大量のデータを読み込んで学習します。このとき、他人の著作物を勝手に学習させてよいのかが問題になります。日本の著作権法(第30条の4)では、原則として「非享受目的(その作品自体を楽しむ目的ではない)」の利用であれば、著作権者の利益を不当に害しない限り、学習データとしての利用が合法とされています。
2. 生成・利用段階のリスク
私たちがAIを使ってコンテンツを生成し、それを公開する段階です。ここで著作権侵害となるかは、主に「依拠性(既存の作品をもとにしているか)」と「類似性(既存の作品と似ているか)」の2点が争点となります。偶然似てしまっただけでもトラブルになる可能性があるため、注意が必要です。
業務利用時に知っておきたい3つのリスク
生成AIを業務で利用する際、著作権以外にも気をつけるべきリスクがあります。主に以下の3つに分類されます。
- 権利侵害(加害リスク):生成したコンテンツが他者の著作権、商標権、意匠権などを侵害してしまうリスク。
- 情報漏えい:入力した機密情報や個人情報がAIの学習データに取り込まれ、他人の回答として出力されてしまうリスク。
- ハルシネーション(もっともらしい嘘):AIが事実と異なる情報を生成し、それを鵜呑みにして誤った情報を発信してしまうリスク。
安全に活用するための具体的な対策とガイドライン
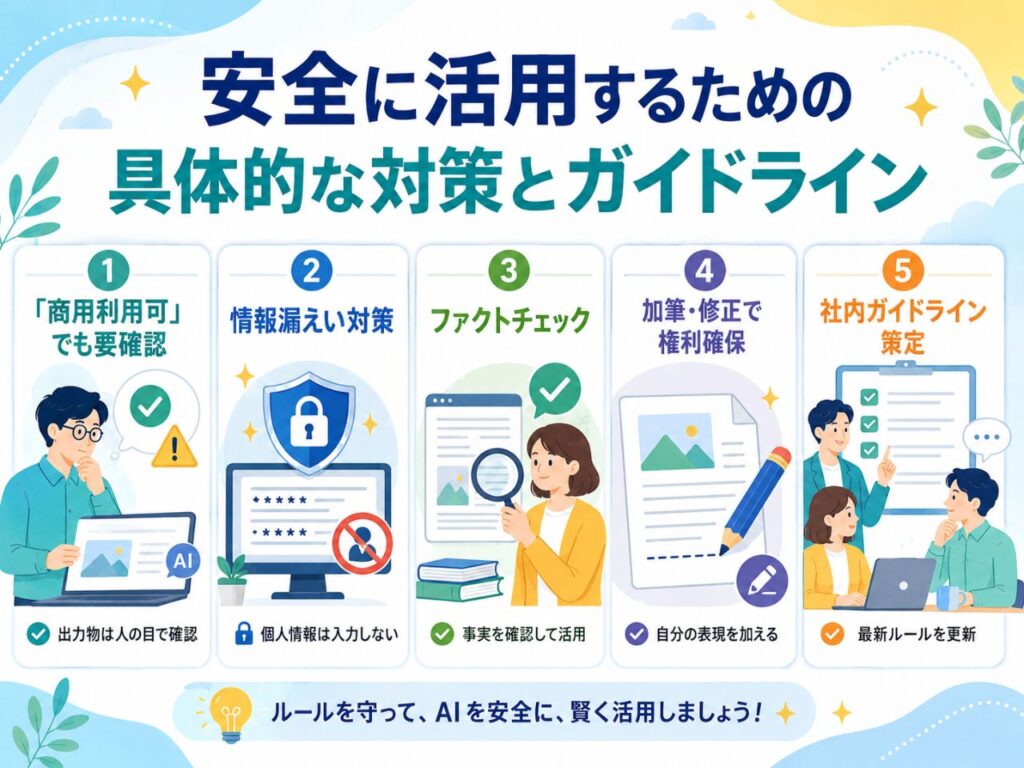
法的トラブルを回避し、安全に生成AIを活用するためには、利用者個人と組織の両面で対策を行う必要があります。
「商用利用可」の落とし穴に注意
多くの生成AIサービスが「商用利用可」を謳っていますが、これはあくまで「サービスの利用規約として商用利用を認める」という意味です。出力されたコンテンツが他者の権利を侵害していないことまで保証しているわけではありません。最終的な確認は人間の目で行う必要があります。
利用者側の具体的な対策
- 情報漏えい対策:入力データが学習に利用されない(オプトアウト機能がある、または学習させない設定にできる)サービスやプランを選択しましょう。また、個人情報取扱事業者が本人の同意なしに個人データを入力し、それが学習などに使われた場合は法律違反となる可能性があるため、個人情報の入力は避けるべきです。
- ハルシネーション対策:出力された内容は鵜呑みにせず、必ず複数の信頼できる情報源で事実確認(ファクトチェック)を行ってください。
- 著作権確保の工夫:AIが生成したものをそのまま利用しても、自分自身の著作権は発生しにくいとされています。権利を確保したい場合は、生成物に人間の手で加筆・修正を加えるプロセスが必要です。
組織としての対策(ガイドラインの策定)
企業やチームでAIを導入する際は、従業員向けの「生成AI利用ガイドライン」を策定することが不可欠です。入力してはいけない情報の定義や、出力物の確認プロセスを明確にし、社内で注意喚起を徹底しましょう。
また、文化庁が2024年3月に取りまとめた「AIと著作権に関する考え方」などの最新の公的情報を定期的にチェックし、ガイドラインをアップデートしていくことも大切です。必要に応じて、外部のAIセキュリティ関連サービス(リスクガバナンス構築支援など)を活用することも一つの有効な手段です。
まとめ
生成AIは非常に便利なツールですが、著作権侵害や情報漏えいなどのリスクと隣り合わせです。以下のポイントを押さえて、安全に活用しましょう。
- AIの著作権問題は「学習段階」と「生成段階」に分けて理解する
- 「商用利用可」=「権利侵害しない」ではないことを強く認識する
- 学習に利用されない設定(オプトアウト)を活用し、機密情報や個人情報を入力しない
- 出力結果はそのまま使わず、必ず人間の目で確認・修正・加筆を行う
- 社内での利用ガイドラインを策定し、ルールを共有・徹底する
正しい知識と対策を身につけることで、法的トラブルを回避し、生成AIのメリットを最大限に引き出して業務に役立てていきましょう。







