会議やインタビューの録音データを文字起こしする際、「Plaud note(プラウドノート)」などの最新AIボイスレコーダーを使うと、発言者ごとにきれいにパート分けされていて驚くことがあります。「声だけで、どうやってAさんとBさんを区別しているの?」と不思議に思ったことはありませんか?
人間なら「今の声は田中さんだ」と感覚的に分かりますが、機械も実は似たような、あるいはもっと複雑な計算を行って声を判別しています。この記事では、AIが音声を「人ごとに分ける」ための技術的な仕組みについて、分かりやすく解説します。
音声データから人を判別する「音源分離」とは?
AIが録音データから「誰が話しているか」を判別したり、混ざった声を分けたりする技術は、専門的には「音源分離」や「話者ダイアライゼーション(Speaker Diarization)」と呼ばれます。
これは、いわば「カクテルパーティー効果」を機械で再現する技術です。
カクテルパーティー効果とは、騒がしいパーティー会場でも、自分が興味のある相手の会話だけを自然と聞き取ることができる人間の能力のことです。
これをAIで実現するために、大きく分けて2つのアプローチが使われています。
1. マイクが複数ある場合:音の「ズレ」を利用する
本格的な会議室用システムなど、マイクが2つ以上ある環境では、それぞれのマイクに音が届くまでの「時間のズレ」や「音の大きさの差」を利用します。
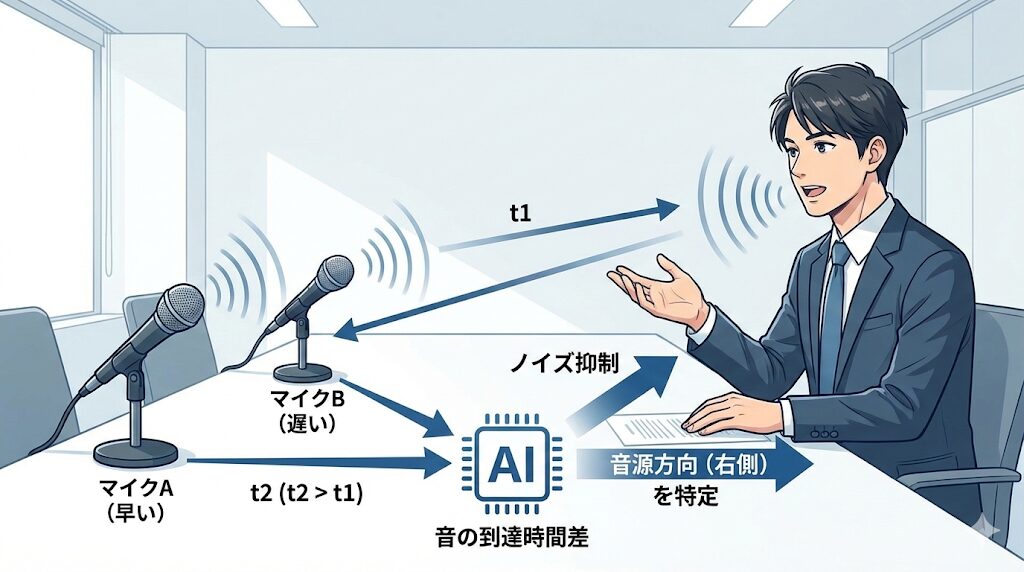
- 線形フィルタリング:マイクAには早く届き、マイクBには遅れて届いた場合、「音源は右側にある」といった位置関係を計算できます。これを応用して、特定の方向からの声だけを拾い、それ以外を抑えることができます。
2. マイクが1つの場合:声の「成分」を利用する
Plaud noteのような薄型レコーダーやスマートフォンの場合、マイクの数は限られます(単一マイクの場合も多いです)。マイクが1つしかないのに、どうやって重なった声を分けているのでしょうか?
ここで使われるのが「非線形フィルタリング」という手法です。
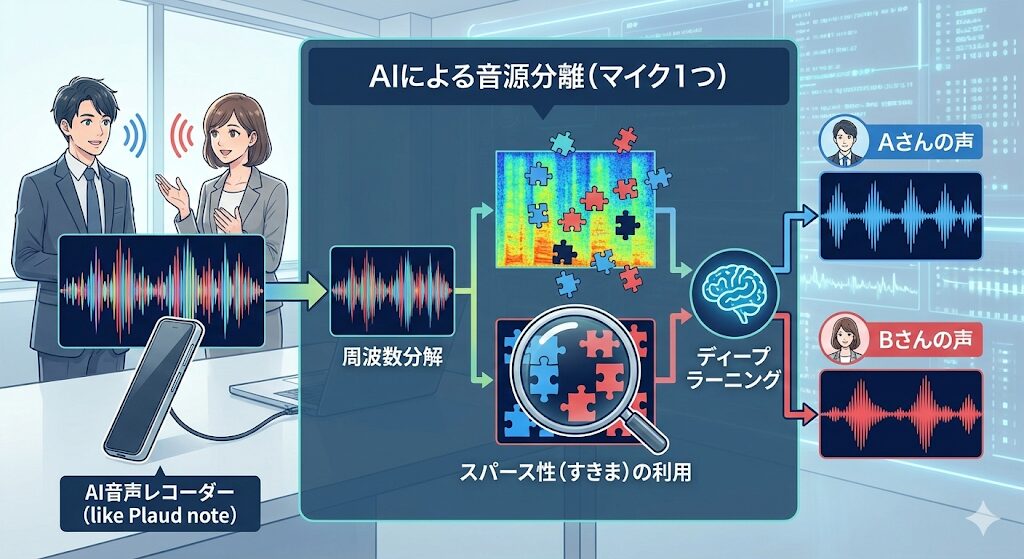
スパース性(すきま)の利用:
音声波形を細かく分析(周波数分解)すると、一見重なって聞こえる声でも、実は「周波数の成分」レベルでは重なっていない部分(すきま)がたくさんあります。
AIはこの「すきま」を見つけ出し、Aさんの成分とBさんの成分をパズルのように分解して抽出します。
ディープラーニングの進化:
近年ではAI(ディープラーニング)の学習により、事前に学習していない人の声であっても、「ここからここまでがひとりの声の特徴だ」と推測して分離する能力が飛躍的に向上しました。
AIはどうやって「声の主」を特定している?
音を分けるだけでなく、「これはAさん、これはBさん」とラベルを貼る作業(話者識別)には、声の特徴分析が使われます。
声の指紋「声紋」を分析
指紋と同じように、声にもその人特有のパターンがあります。これを「声紋」と呼びます。AIは録音データから以下のような情報を瞬時に数値化しています。
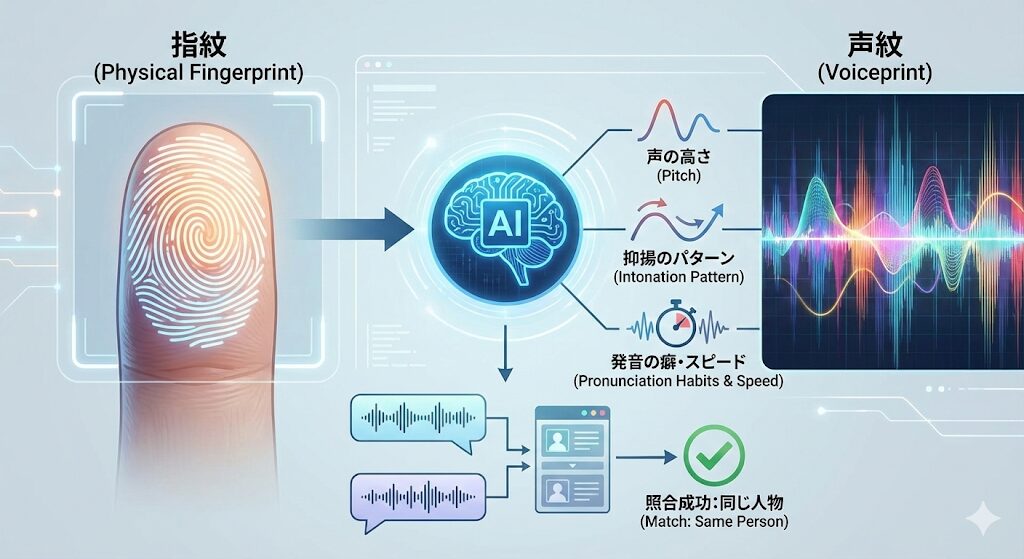
- 声の高さ(ピッチ)
- 抑揚のパターン
- 発音の癖やスピード
これらのデータを照合し、「この発言とさっきの発言は、数値的な特徴が似ているから同じ人物だ」と判断して、Speaker A、Speaker Bといったタグ付けを行っているのです。
技術の進化と今後の展望
技術コラムなどを発信しているLaboro.AIの情報によると、2016年頃から「Deep Clustering」という手法が提案され、AIが未知の話者でも分離できるような技術革新が起きました。さらに2018年以降はリアルタイム処理が可能な技術も登場しており、これが現在の便利なAIボイスレコーダー製品の基礎となっています。
また、AmiVoiceのような高度な音声認識APIでは、単に文字にするだけでなく、こうした話者分離の機能をパッケージとして提供しています。アプリ開発者はこれらを利用することで、高精度な「書き起こし&話者識別」機能を製品に組み込むことができるようになっています。
まとめ
Plaud noteなどのAIレコーダーが「相当判別してくれている」と感じるのは、単なる録音機ではなく、「音の成分分解(音源分離)」と「声の特徴分析(話者識別)」という高度なAI処理を裏側で行っているからです。
特にディープラーニングの進化により、マイクが少ない小型デバイスでも、複雑な会話をきれいに分けられるようになってきています。今後さらに精度が上がれば、騒がしいカフェでの会議でも、完璧な議事録が自動で作れるようになるかもしれません。