
業務で扱う顧客データやログファイルに含まれる「個人情報」。
プライバシー保護や法令遵守のためにマスキング(黒塗り)処理が必要になる場面は多いですが、手作業での修正は膨大な時間がかかり、見落としのリスクもつきまといます。
「システム側で自動的に黒塗りしてくれたらいいのに」と考えたことはないでしょうか。
この記事では、システムが個人情報を自動検出しマスキングする仕組みと、GoogleやMicrosoftが提供している具体的なサービス、そして導入時のポイントについて解説します。
個人情報を自動でマスキングする「仕組み」とは?
システムが個人情報を自動的に処理する場合、大きく分けて「検出(見つける)」と「加工(隠す)」の2つのステップが行われます。
1. 検出:どうやって個人情報を見つけるのか
システムは主に以下の方法を組み合わせて、どれが個人情報(PII:Personal Identifiable Information)かを判断しています。
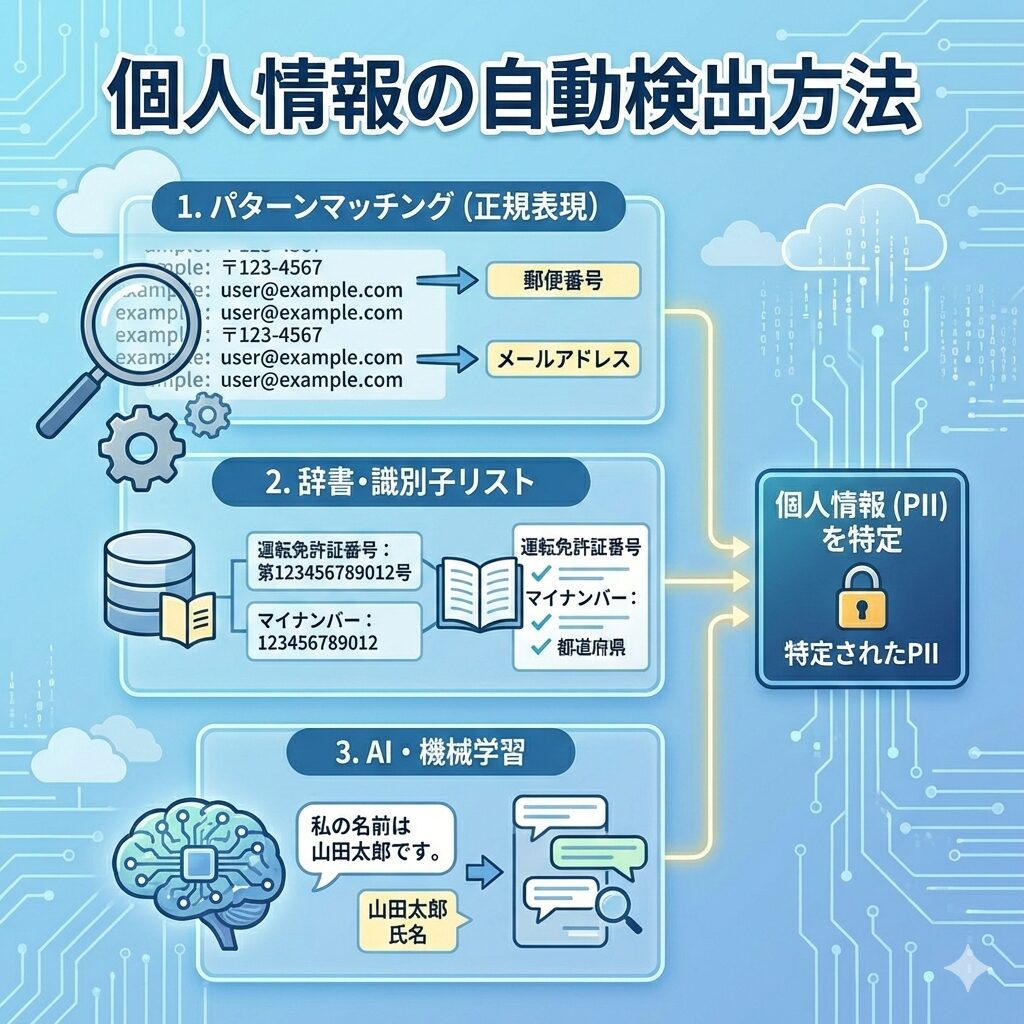
パターンマッチング(正規表現):
「3桁-4桁」の郵便番号や、メールアドレスの形式(@を含む文字列)など、決まった形式のデータを機械的に探します。
辞書・識別子リスト:
国や地域ごとの運転免許証番号、マイナンバー、都道府県名など、あらかじめ登録されたデータ形式と照合します。
AI・機械学習:
文脈(コンテキスト)を解析し、「私の名前は〇〇です」といった自然言語の中から氏名を特定したり、会話ログから個人情報を抽出したりします。
2. 加工:黒塗りだけではない「隠し方」の種類
「隠す」といっても、単に黒く塗りつぶすだけではありません。データの利用目的に応じて、いくつかの手法が使い分けられます。
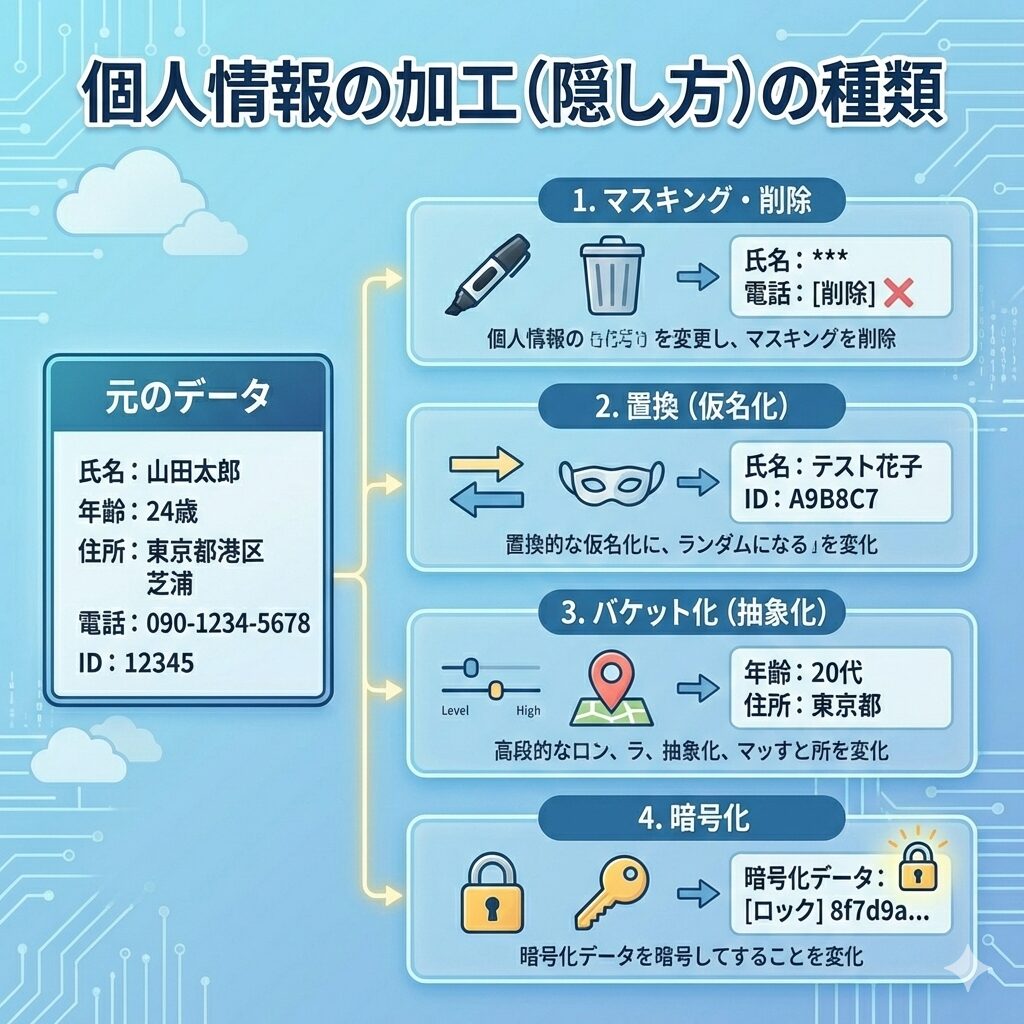
マスキング・削除:
文字を「***」や「###」に置き換えたり、データそのものを削除したりします。最も一般的な方法です。
置換(仮名化):
実在しないランダムな名前やIDに置き換えます。データの形式を崩さずにテストデータとして使いたい場合などに有効です。
バケット化(抽象化):
「24歳」を「20代」、「東京都港区」を「東京都」のように、個人の特定は防ぎつつ分析に使える粒度に丸める手法です。
暗号化:
特定の鍵がないと元の情報に戻せないように変換します。
GoogleやMicrosoftが提供する代表的なサービス
自社でゼロから開発しなくても、クラウドベンダーが提供するAPIを利用することで、高度な自動マスキング機能をシステムに組み込むことができます。ここでは代表的な2つのサービスを紹介します。
Google Cloud – Sensitive Data Protection
Googleが提供する、機密データの検出と保護に特化したサービスです(旧称:Cloud DLP)。
https://cloud.google.com/security/products/sensitive-data-protection?hl=ja
【主な特徴】
- 高度な匿名化技術: 単なるマスキングだけでなく、データの統計的な有用性を維持する「バケット化」や、日付の順序関係を保ったままランダムにずらす「日付シフト」など、分析用途に適した変換が可能です。
- 再識別可能な暗号化(FPE): データの形式(長さや文字セット)を維持したまま暗号化でき、必要な権限を持つ管理者だけが元のデータに復元できる仕組みを持っています。
- Google Workspaceとの関係: Google Workspace(GmailやDrive)のEnterpriseプラン等でもDLP(データ損失防止)機能は提供されていますが、システム開発や大量データの自動加工を行いたい場合は、このGoogle Cloudのサービスを利用するのが一般的です。
Microsoft Azure – Language PII Detection
MicrosoftのAIサービスの一部で、テキストやドキュメント内の個人情報を検出・編集する機能です。
【主な特徴】
- ファイルの直接読み込み: Word(.docx)やPDF、テキストファイルをそのまま読み込んで解析できるため、前処理の手間が省けます。
- 会話データへの対応: 「Conversation PII」というモードがあり、チャットログや音声文字起こしなど、口語体のテキストからも精度高く個人情報を検出できます。
- 柔軟な編集ポリシー: 完全に隠す(マスク)だけでなく、エンティティの種類([電話番号]など)に置き換えるといった制御が可能です。
導入コストと利用のポイント
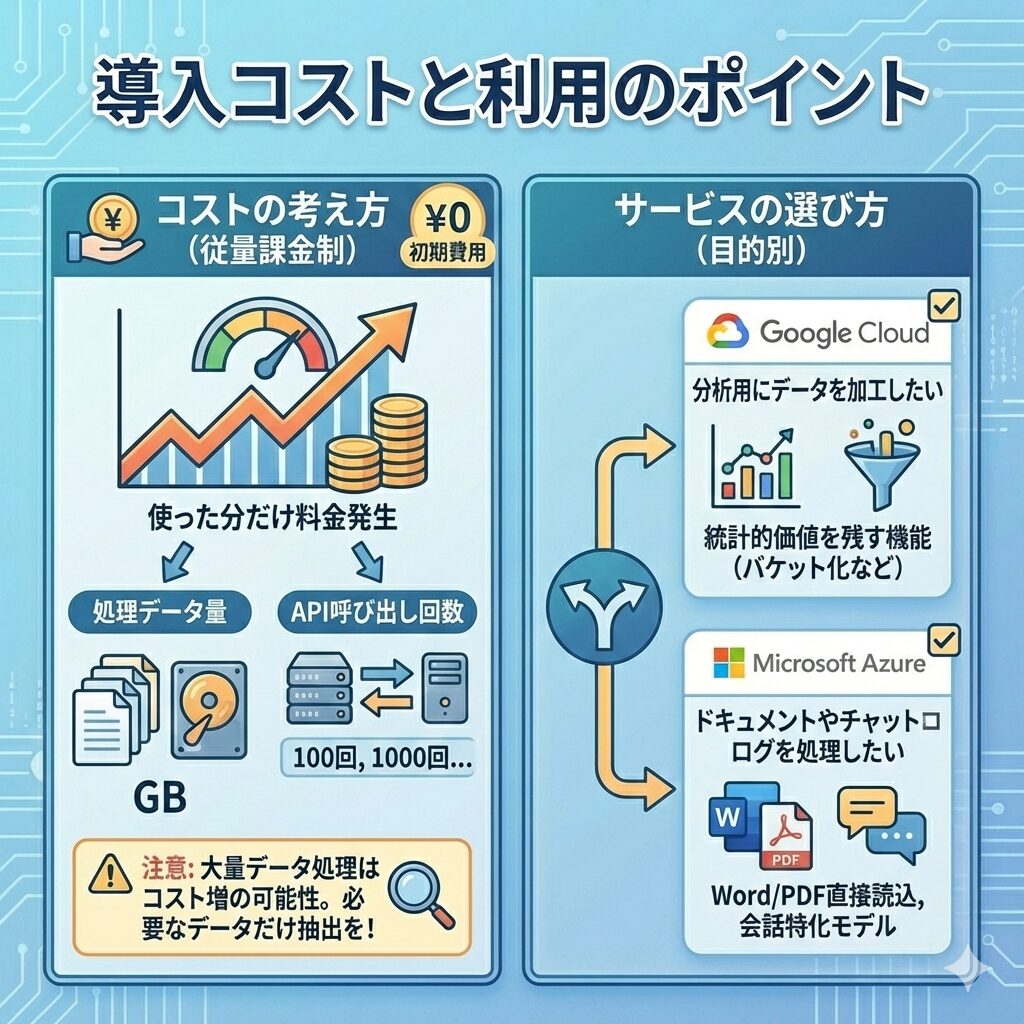
コストの考え方
これらのクラウドサービスは、一般的に「従量課金制」が採用されています。初期費用はかからない場合が多いですが、以下の要素によって料金が変動します。
- 処理するデータ量: テキストの文字数や、画像の枚数、ファイルサイズ(GB単位)など。
- APIの呼び出し回数: システムが何回サービスを利用したか。
例えばGoogle Cloudの場合、一度に大量のデータを検査するとコストがかさむ可能性があるため、必要なデータだけを抽出して処理する工夫が求められます。
サービスの選び方
どちらのサービスを利用すべきかは、目的によって異なります。
- 分析用にデータを加工したい場合:
データの統計的な価値を残せる機能(バケット化など)が豊富なGoogle Cloudが適しています。 - ドキュメントやチャットログを処理したい場合:
Word/PDFの直接読み込みや会話特化モデルを持つMicrosoft Azureが便利です。
まとめ
システムによる個人情報の自動マスキングは、業務効率化だけでなく、ヒューマンエラーによる情報漏洩を防ぐためにも有効な手段です。
GoogleやMicrosoftなどのクラウドサービスを活用すれば、高度なAI技術をすぐに利用できます。「分析に使いたいのか」「ファイルをそのまま処理したいのか」といった目的に合わせて、適切なサービスを検討してみてください。







