
Googleの生成AI「Gemini」をはじめ、AIによる音楽生成技術が急速に進化しています。
そこで注目されているのが、AIで作られたコンテンツであることを証明する電子透かし技術「SynthID(シンスID)」です。
「この音楽にはSynthIDが埋め込まれている」と聞いたとき、多くの人が疑問に思うのが「その透かし情報は、人間が聴いて分かるものなのか?」ということではないでしょうか。
結論から言うと、SynthIDの情報は人間の耳では全く聞き取ることができません。
この記事では、SynthIDがどのように埋め込まれており、人間が読み取れない情報をどうやって確認するのか、その仕組みと確認方法について分かりやすく解説します。
結論:SynthIDの情報は人間には「知覚できない」
Geminiなどで作成された音楽に埋め込まれるSynthIDは、開発元のGoogle DeepMindによって「人間には知覚不可能(Imperceptible)」になるように設計されています。
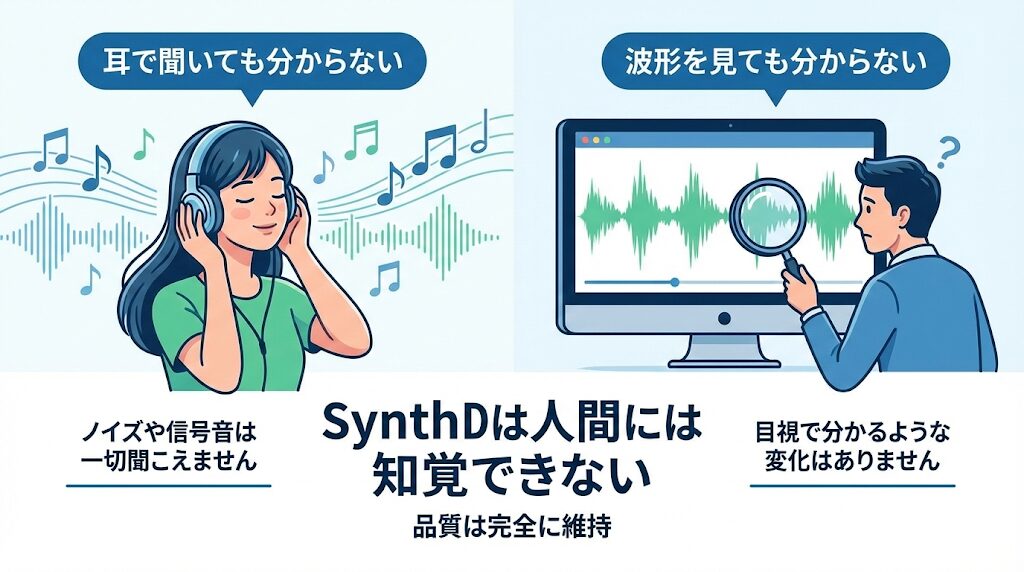
つまり、以下のような方法では透かし情報を読み取ることはできません。
耳で聞く:音楽を再生しても、特定のノイズや信号音は一切聞こえません。
波形を見る:一般的な音楽編集ソフトで波形を見ても、目視で分かるような変化はありません。
SynthIDの最大の特徴は、「コンテンツの品質(音質)を完全に維持したまま」情報を埋め込む点にあります。
そのため、人間が五感を使ってその存在を確認しようとしても、AIで作られたものか、人間が作ったものかを区別することは不可能なのです。
どうやってAI生成音楽だと区別するの?
人間には感知できないSynthIDですが、専用のツールを使えば明確に「読み取る」ことができます。
人間が直接解読するのではなく、「AIを使ってAIの痕跡を見つける」というアプローチをとります。
1. 専用の検出ツール(SynthID Detector)を使用する
Googleは、SynthIDが埋め込まれているかを判定するための検出ツール(SynthID Detector)を開発しています。
ユーザーが音楽ファイルや画像ファイルをこのツールにアップロードすると、システムが自動的に解析を行い、「AIによって生成された可能性が高いか」を判定してくれます。
現在はベータテスト版などが一部で提供されており、将来的にはより広く利用可能になることが期待されています。
2. Geminiなどのプラットフォーム上で確認する
Geminiのチャット画面など、Googleのサービス上でも確認機能の実装が進められています。

例えば、画像や動画の場合、Geminiにファイルをアップロードして「これはGoogleのAIで作られたものですか?」と尋ねることで、システムが内部的に透かしをチェックし、回答してくれる機能があります。
音楽(音声)についても同様の仕組みで、システム側が透かしを読み取ってユーザーに教えてくれる形になります。
SynthIDの仕組みと「消えにくさ」
なぜ人間には分からないのに、機械には読み取れるのでしょうか? その秘密はデータの埋め込み方にあります。
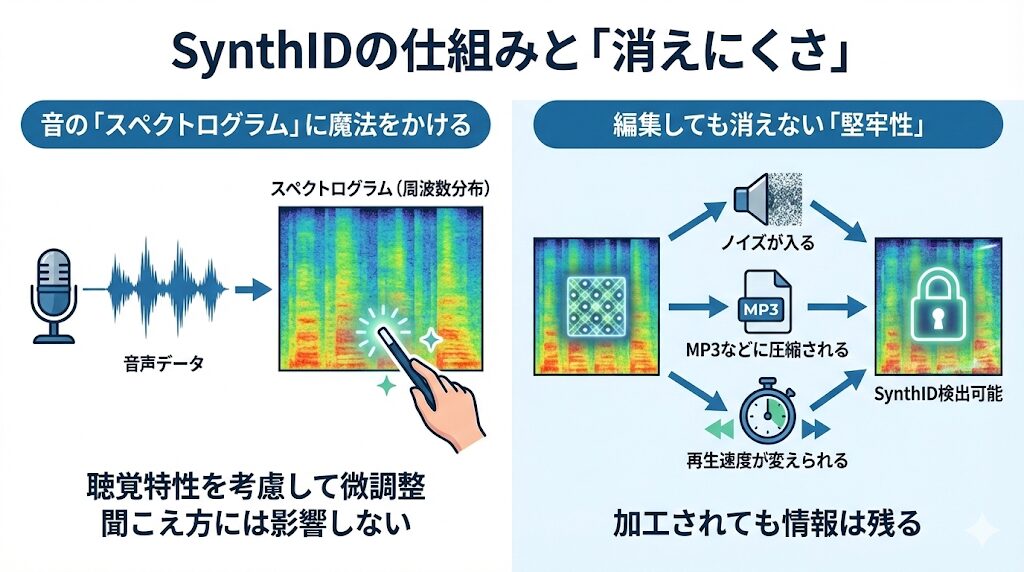
音の「スペクトログラム」に魔法をかける
音声データの場合、SynthIDは音を「スペクトログラム(周波数分布の可視化データ)」に変換し、そこに透かし情報を埋め込みます。
このとき、人間の聴覚特性を考慮し、「聞こえ方には影響しないが、データとしては確実に存在する」範囲で微調整を行います。
これにより、高音質な音楽体験を損なうことなく、識別情報を付与することができるのです。
編集しても消えない「堅牢性」
SynthIDのもう一つの凄さは、多少の編集を加えても情報が消えないことです。
- ノイズが入る
- MP3などに圧縮される
- 再生速度が変えられる
一般的な透かし技術であれば、こうした加工で情報が壊れてしまうことがありますが、SynthIDはこれらの変更が行われても検出可能な状態で残るように作られています。
まとめ
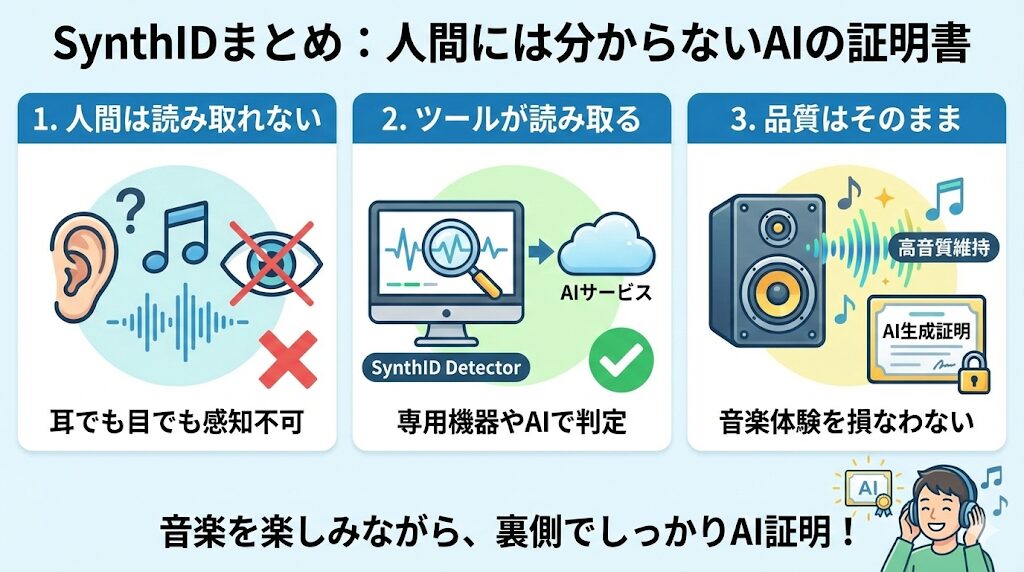
Geminiなどで作られた音楽の透かし「SynthID」について、人間がどう読み取るのかという疑問への答えは以下の通りです。
- 人間は読み取れない:耳で聞いても目で見ても、透かしの存在は分かりません。
- ツールが読み取る:専用の検出器やGoogleのAIサービスを通じて、機械的に判定します。
- 品質はそのまま:音楽としてのクオリティを損なわずに、著作権や生成元の証明を行います。
SynthIDは、私たちが普段楽しむ音楽体験を邪魔することなく、裏側でしっかりと「これはAIが作ったものです」という証明書を持ってくれている技術だと言えます。
参考リンク
Transforming the future of music creation — Google DeepMind
Scalable watermarking for identifying large language model outputs | Nature







